During the ninth month of the year, enjoy nine of the latest additions to the John Martin Rare Book Room (JMRBR) collection. Contact JMRBR Curator Damien Ihrig at damien-ihrig@uiowa.edu or 319-335-9154 to see these books or plan a visit to JMRBR. Want to receive medical history and curator selections in your inbox? Subscribe to the Friends of the JMRBR monthly newsletter!
1. Manuel des plantes médicinales and Herbier médical
This is a two-volume set of botanical works from Alexandre Gautier. The text of Manuel lists indigenous plants used in medicine, with an emphasis on how to properly store and prepare them for the highest efficacy. The real gem, though, is the 214 plate, hand-colored Herbier, with beautiful illustrations to accompany many of the plants listed in the Manuel. Only one other hand-colored copy is known to exist and it’s at the BIU Santé Médecine in Paris. If you’re lucky enough to be reading this while strolling down the Champs-Élysées, you should pop over La Seine to see that one for yourself. If not, feel free to pop over La Iowa River to see ours!
GAUTIER, LOUIS-ALEXANDRE (fl. 1822). Manuel des plantes médicinales AND Herbier médical: supplément au Manuel des plantes médicinales. Both printed in Paris by Audot, 1822. Both 18 cm tall.
2. Traité de la peste
The French herbalist and apothecary, Nicolas Houel (ca. 1524–1587), a distinguished figure in the history of 16th-century Parisian pharmacy, was known not only for his pharmaceutical expertise but also for his contributions as an artist, collector, and philanthropist. Driven by a commitment to social welfare, Houel helped establish an institution dedicated to caring for the sick, impoverished, and orphaned. The institution included a chapel, orphanage, hospital, apothecary, and a medicinal plant garden. This garden later became the site of the Jardin des Plantes, now home to the Museum of Natural History. Houel was also a prolific writer, producing numerous works on cultural, artistic, and scientific subjects. Among his most notable publications are a treatise on Theriac and Mithridate (classical poison antidotes) and this treatise is on the plague.
HOUEL, NICOLAS (ca. 1524–1587). Traité de la peste auquel est amplement discouru de l’origine, cause, signes, preservation & curation d’icelle. Printed in Paris by Galiot du Pré, 1573. 17 cm tall.
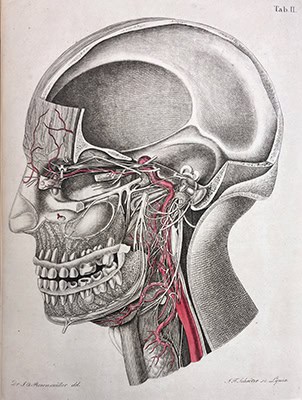
3. Beschreibung des fünften nervenpaares
Though relatively obscure, Bock’s work holds significant value for its early contribution to the understanding of neural circuitry—an idea now widely accepted thanks to neuroanatomical evidence. Notably, Bock identified the connections between the sympathetic nerves and the autonomic ganglia associated with the eye, diverging from the views of Meckel, who was then considered the leading authority on the anatomy of the fifth cranial nerve. Equally noteworthy are the innovative techniques Bock employed and the clarity and elegance of his anatomical presentations. As an educator, Bock was distinguished by his ability to present anatomical structures with exceptional clarity. As a prosector, his technical skill in specimen preparation greatly enriched the anatomical museum in Leipzig, leaving a lasting legacy in both pedagogy and anatomical research.
BOCK, AUGUST CARL (1782–1833). Beschreibung des fünften nervenpaares. Printed in Meissen by Friedrich Wilhem Goedsche, 1817. Bound with: Nachtrag zu der Beschreibung des fünften Hirnnerven. Printed in Meissen by Friedrich Wilhem Goedsche, 1821. 44 cm tall.
4. Experimental philosophy
This is a first edition of the first book in English on microscopy. It beat Hooke’s Micrographia by one year! It is clear that Power and Hooke shared notes, with Power writing in Experimental philosophy that Hooke confirmed some of his observations.
POWER, HENRY(1623–1668). Experimental philosophy. In three books: containing new experiments microscopical, mercurial, magnetical. Printed in London by T. Roycroft, for John Martin, and James Allestry, at the Bell in S. Pauls Church-yard, 1664. 21 cm tall.
5. Manuel Du Vaccinateur
Manuel documents the history of smallpox vaccination in France, featuring a question-and-answer section on its administration and safety, along with official government notices regarding its rollout in the Ardèche province. Delaroque was a strong advocate for the vaccine’s effectiveness and played a key role in translating the works of English pioneer Edward Jenner into French. Delaroque presented this particular copy to Matthieu Pierre Louis Duret (1758–1841), a fellow Jenner disciple and the appointed vaccinator for the county of Annonay. Most pages are printed on light blue paper and bear a blacked-out tax stamp. One handwritten correction appears in the text.
DELAROQUE, JOSEPH (fl. 1808). Manuel Du Vaccinateur. Printed in Privas De l’imprimerie de F. Agard, 1808. 22 cm tall
6. Instruction familiere & trés-facile
First published in 1677, Instruction familière & très-facile is a practical manual for midwives, written in a question-and-answer format to guide them through emergencies without relying on surgeons. Its author, Marguerite du Tertre de La Marche, was a leading midwife at the Hôtel-Dieu in Paris from 1670 to 1686. A student of Louise Bourgeois, La Marche reformed midwifery education by introducing a structured three-month training program. The 1710 edition of Instruction familiere includes Secrets choisis by Bourgeois, a collection of 280 home remedies and cosmetic recipes. Divided into five sections, it covers internal diseases, external ailments, women’s health, beauty treatments, and miscellaneous cures, including instructions for preparing waxed cloths and plasters.
LA MARCHE, MARGUERITE (1638–1706). Instruction familiere & trés-facile, faite par Questions & Réponses touchant toutes les choses principales qu’vne Sage-femme doit sçavoir pour l’exercice de son Art. Printed in Paris for the author, 1677. 17 cm tall.
7. De monstrorum Natura, Caussis, et differentiis
Liceti’s most renowned medical work is De monstrorum Natura, Caussis, et differentiis, first published in Padua in 1616 and reissued in 1634 with elaborate illustrations. In this groundbreaking text, Liceti offered one of the earliest systematic classifications of developmental disorders, organizing them by physical form rather than presumed cause—a significant departure from earlier approaches. While morphology guided his taxonomy, Liceti also proposed physiological explanations for these malformations. He cited factors such as a constricted uterus, placental irregularities, and the adhesion of amniotic fluid to the embryo as potential contributors. He was also among the first to suggest that fetal diseases could directly result in congenital disorders, marking a pivotal moment in the history of embryology and teratology.
LICETI, FORTUNIO (1577–1657). De monstrorum Natura, Caussis, et differentiis. Printed in Padua by Paolo Frambotto, 1634. 20 cm tall.
8. Disputa del lo eccellentissimo filosofo
This book is the Italian edition of the account of a young German, Margaetha Weiss, who suffered from the first medically-substantiated case of anorexia. Examined by several physicians, it was the Italian physician Porzio who determined that her condition could be explained by natural causes, rather than the moral or mystical causes diagnosed by the other physicians and agents of the Church. His original Latin edition was translated into this Italian edition by a friend of Porzio’s. It includes information on Weiss that was not included in the Latin and German editions.
PORZIO, SIMONE (1496–1554). Disputa del lo eccellentissimo filosofo [De puella germanica]. Printed in Florence by Lorenzo Torrentino, 1551. 17 cm tall.
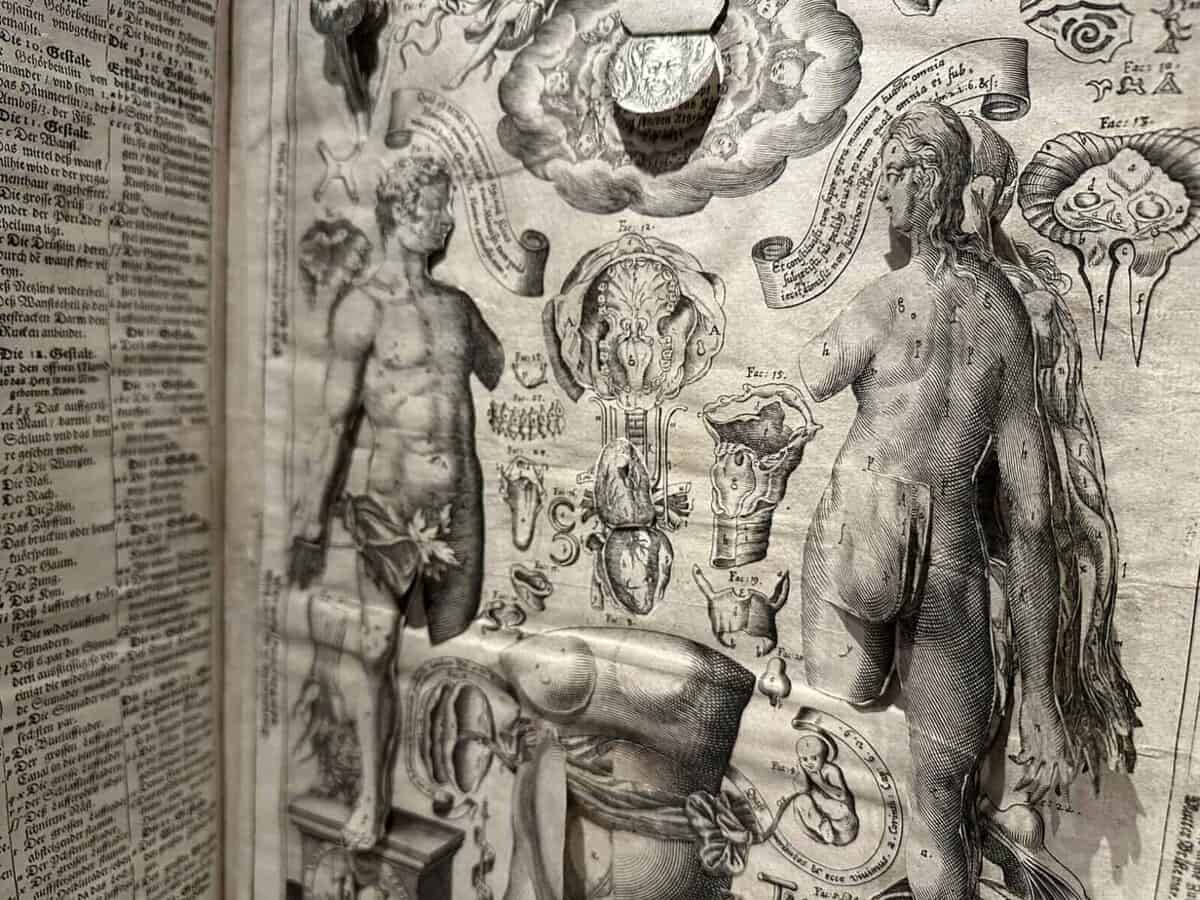
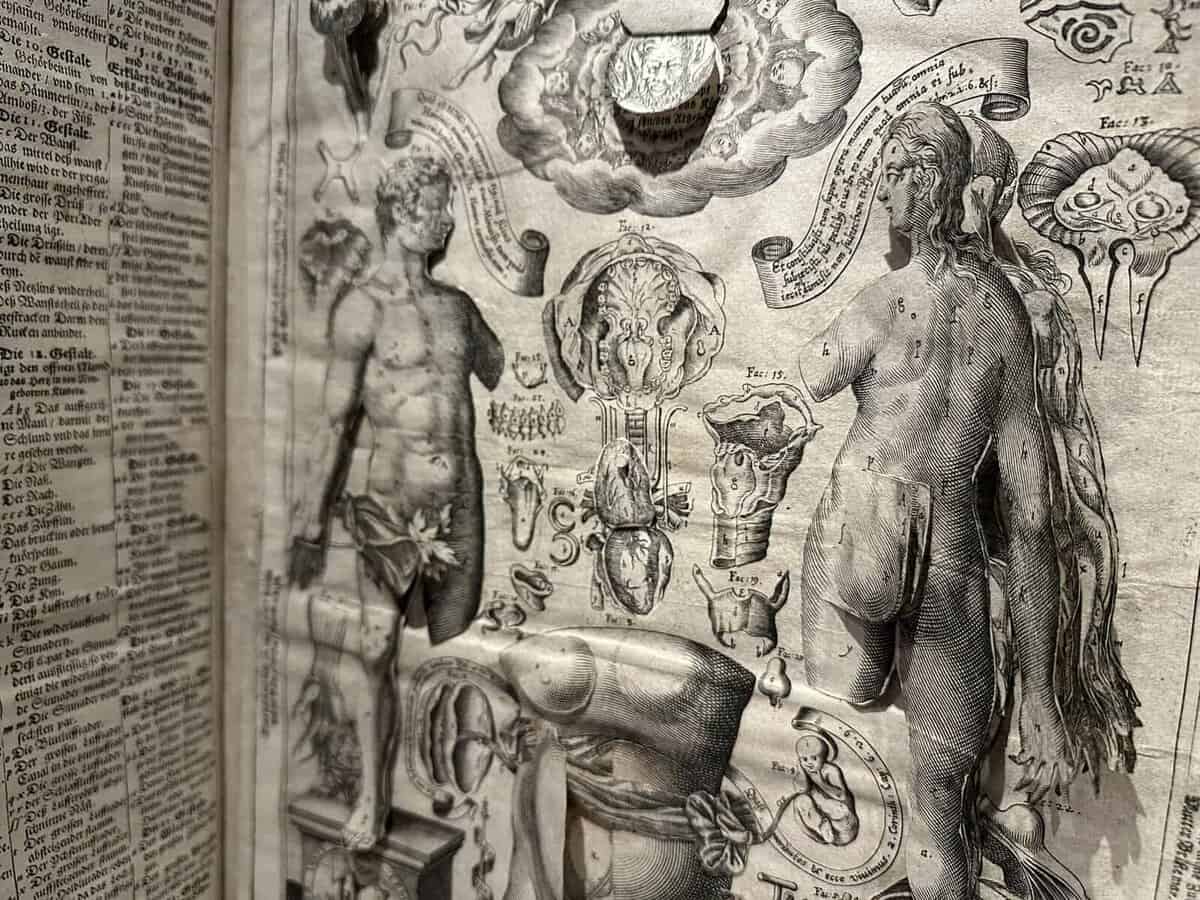
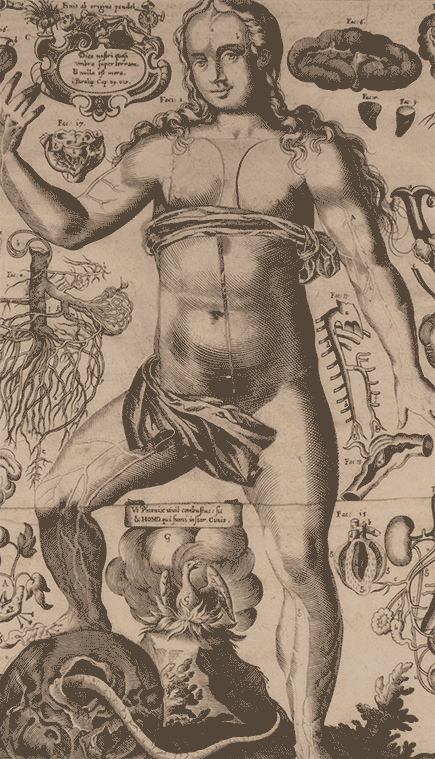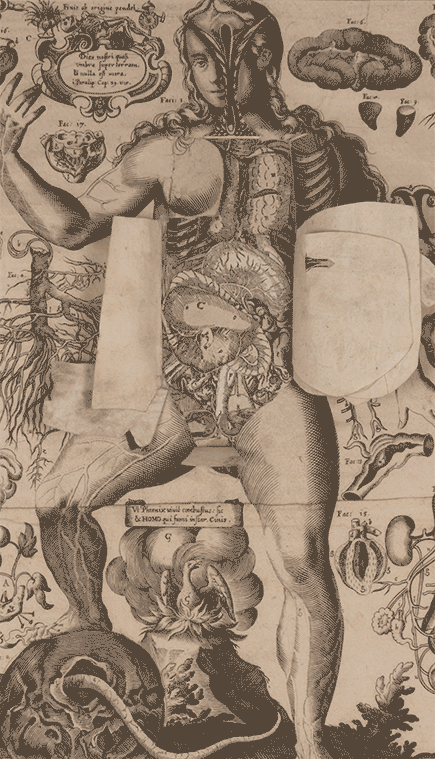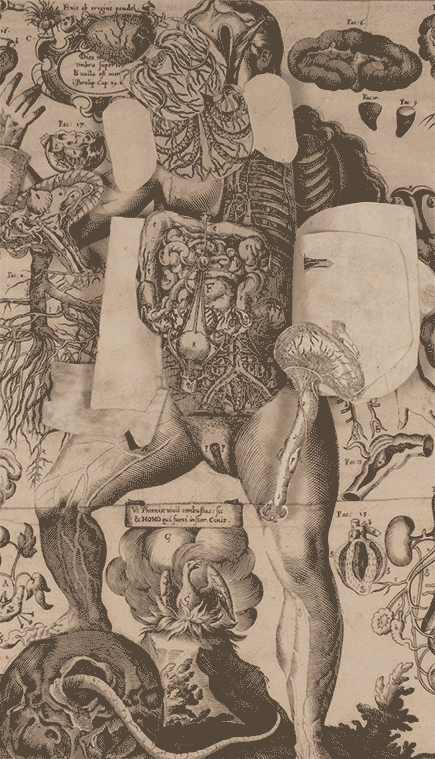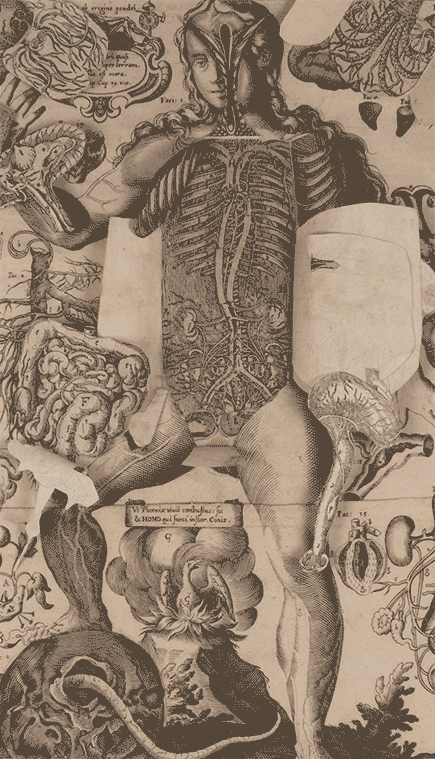
9. Le corps de l’homme
Dr. Jules Galet, a clinical head at the Montpellier Faculty of Medicine, published this widely circulated anatomy and physiology manual in serialized parts between 1835 and 1841. Each installment contained 24 pages and six plates, designed to make the subject accessible to all social classes. The second edition, though uncolored, remains visually compelling. Despite the title page’s claim of 200 plates, the work matches the first edition’s collation, comprising 193 interleaved plates numbered 1–177, plus a supplementary section of 10 plates illustrating the systems of Gall and Lavater. It also includes portraits of Paolo Mascagni, William Harvey, Franz Joseph Gall, and Johann Caspar Lavater, along with two unnumbered anatomical plates and a frontispiece. The volumes are organized into four sections: 1) Digestive, absorbent, and respiratory systems, including their functions; 2) Respiratory system and circulation; 3) Musculoskeletal system—covering bones, joints, muscles, and voluntary movement—alongside Lavater’s physiognomic theories; 4) Nervous system, reproduction, innervation, Gall’s phrenological system, and embryology.
GALET, JULES (1583–1632). Le corps de l’homme, traité complet d’anatomie et de physiologie humaines. Four volumes in two. Printed in Paris for the author, 1844. 28 cm tall.