
Project Background:
Demonstrating strong control over one’s own life is morally encouraged and sometimes required by American society. Potent as this tenet shapes individual behaviors, it can only remain strong through repeated instantiations in our daily lives. To understand how the value of having control is woven into American’s mainstream individualistic culture, I explore its manifestation in one of the major conduits for conveying social values (albeit its diminishing influence these days) – newspapers. For this project, I gathered 3669 newspaper articles published in the U.S. from 1979 to 2020 that include the phrase “sense of control” through Next Uni (previously called LexisNexis Academic). By conducting text and network analysis, I will first examine different life aspects or topics associated with the discussion of control, as well as their variation along the time (what aspects or topics become increasingly/decreasingly/no long related to “sense of control”?). Additionally, the usage of the phrase will be examined syntactically to gauge the ways in which different social actors engage with the concept to act on the object of interest, and semantically to explore the attitudinal aspects correlate with the phrase.
Project Objectives:
-
Explore topics associated with the “control” discourse by time periods:
-
-
Generate text co-occurrence network by time periods and detect the network community structure to extract topics.
-
Visualize the proportion of texts devoted to each topic by time to demonstrate the topics’ variation in significance related to control as time flows (e.g. Rule et al. 2015).
-
-
Investigate the usage of the phrase “sense of control” to detect the major patterns people use it in navigating through their lives.
The current stage of the analysis:
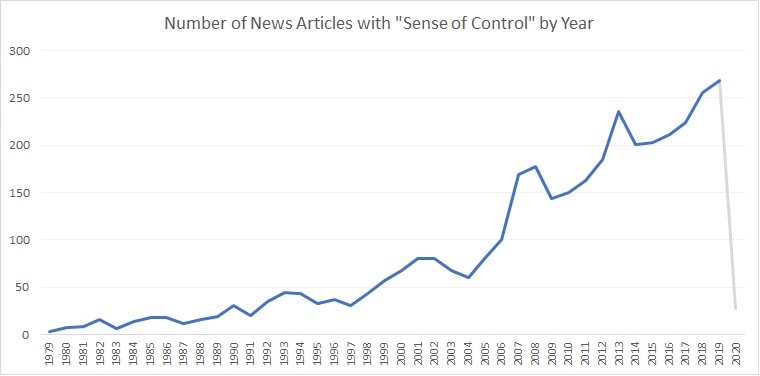
During the first few weeks of the fellowship, I have finished the basic cleaning of the articles. A basic finding is the number of articles with the phrase “sense of control” increase by years. Although it could be a result of an overall increase in the total number of published news articles. My collection of articles only includes the ones published by 2020 January 20th, so the number of articles from 2020 is fairly small.
In addition, I have been working on exploring embedded topics. Nexis Uni’s news articles entail information segments that drastically saved computing resources and time for me. More specifically, for each article, there is a “Subject” section includes categories and their individual relevance to the article (presented in percentages). An example is as follows:
Index: 1865Title: Appraisal System for Data Processing Functions Devised by Bank ConsultantSubject: {‘BANKING & FINANCE ASSOCIATIONS’: 0.9, ‘ASSOCIATIONS & ORGANIZATIONS’: 0.89, ‘BANKING & FINANCE SECTOR PERFORMANCE’: 0.78, ‘MANAGERS & SUPERVISORS’: 0.76, ‘CONFERENCES & CONVENTIONS’: 0.75, ‘INTERVIEWS’: 0.71}
Informative as this source is, many of the subject labels are too detail-oriented and fragmented that still obscure the major aspects in which “sense of control” is discussed. Therefore, I decided to further categorize these labels. As manual labeling may include bias, I mainly rely on network analysis techniques to explore the topics embedded within these texts. More specifically, I created co-occurrence networks by time periods with this source of information (subject labels listed in the same article is considered co-occurring, thus related). Once the networks are generated, I use the Louvain community detection algorithm to reveal the cohesive clusters within these network structures. The emergence of these clusters is used to form summary topics through human interpretation. In the following, I present an example based on articles published during 1979-1985.
 The 12 colored clusters represent algorithm-detected network communities. Based on the individual elements in each cluster, I am able to form topics like “music” (the light forest green bubble on the bottom left), “sports injury” (the pink cluster on the bottom center), and “crime-related mental health issues and treatment” (the red cluster on the upper right). Some of the clusters overlap as they entail the same labels which work as bridges.
The 12 colored clusters represent algorithm-detected network communities. Based on the individual elements in each cluster, I am able to form topics like “music” (the light forest green bubble on the bottom left), “sports injury” (the pink cluster on the bottom center), and “crime-related mental health issues and treatment” (the red cluster on the upper right). Some of the clusters overlap as they entail the same labels which work as bridges.Next Steps:
I will repeat the aforementioned analysis on the rest of the data to further detect emerging topics and how they vary across time.
Once all the topics are extracted, I will also start to calculate the proportion of text devoted to each topic by year (objective 1.2). The eventual product will be a graph demonstrate the shifts of the relative proportion of topics in the corpus by time.
The second stage of this project, as mentioned earlier, will dive into the main body section of each article and examine texts around the phrase “sense of control”. I will find and extract S-A-O (subject-action-object) triplets from texts most proximate to the control phrase and detect common patterns. The aim is to understand how individuals or groups engage with the phrase to make sense/justify/act on their experiences. Besides the syntactic structure, I will also conduct sentiment analysis on texts most proximate to the control phrase to examine the implicit emotional and attitudinal aspects in discussions of control. The central question to answer with this analysis is whether owning a strong sense of control has gained increasing positivity over time. The changes in control-related sentiment will also be visualized.
Most of the analyses were and will be done with python and R. I have been using python for data cleaning while R for network analysis and visualization during the first part of the project. In the second part, as machine-learning techniques are involved, I will use Python’s scikit-learn package to continue my analysis. There is still much to learn and I am looking forward to becoming more proficient in text analysis during my fellowship experience.
Reference:
Rule A, Cointet J-P, Bearman PS. 2015. Lexical shifts, substantive changes, and continuity in State of the Union discourse, 1790–2014.PNAS112:10837–44