Some thoughts on methods and tools.
Here is the process that I have used to analyze the WOAH database as a network. Let’s start with a sample entry:

http://woah.lib.uiowa.edu/explore/
I point to the 5th field, “Women in the…” and begin the data collection and conversion process there. Entries for this field vary in length from 0 to 238 words in at least 3 languages (though mostly English). I supplement these words with the “Associated Subjects” list from each woman’s Worldcat Identities entry. Here are Dr. Barnes’:

https://www.worldcat.org/identities/lccn-no2017130793/
The goal of this step is to both help add points of contact between scholars and to fill some details into more specialized topics. These additions are particularly helpful when a scholar has nothing in the “Research Interest” field but lots of publications. Of course, plenty of women don’t have Worldcat Identity entries yet, and the number of words tends to be related to how many publications a scholar has. Still, between the original entry and the Worldcat supplements, woman had some words to work with.
It is worth noting at this stage that neither the “Research Interest” field nor the “Associated Subjects” are definite, uniform and authoritative. Common names seem to confuse Worldcat, take Dr. Anna Clark of Christ Church Oxford:
WOAH

http://woah.lib.uiowa.edu/explore/
Worldcat Identities

https://www.worldcat.org/identities/lccn-nr2005018755/
This word list appears to include topics found in books by 3 or 4 entirely different authors with very similar names. I have not yet cleaned out the irregularities, hoping that irregular words like “Florida” will not find a connection in another entry. As WOAH grows and continues to expand outside of Ancient Mediterranean historians, more careful steps will be necessary. In this case, Worldcat is adding a lot of noise or misinformation (Dr. Clark may make a number of false connections through “Military”, “Army” and “Soldiers”) to gain “Cults”, “Historiography”, “Rome” and “Empire” (and “Empire” might be misleading too, compared to her focus on the late Roman Republic).
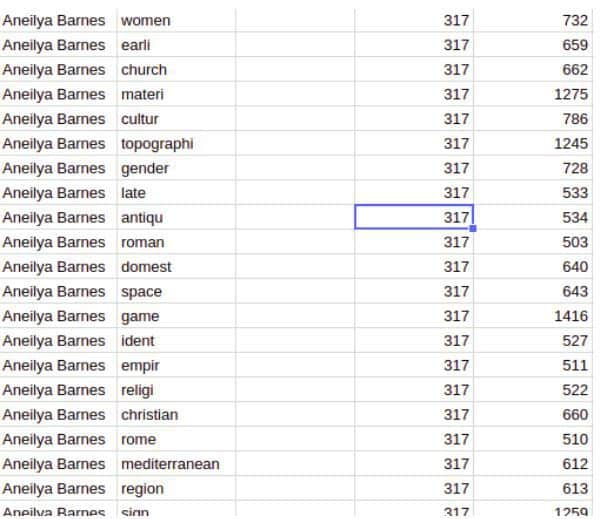
Aware of such problems, let’s move on. I used R’s tm package to remove stop words and stem the words:
(Dr. Barnes again)
Women in the early church, material culture, topography, gender, late antiquity, Roman domestic space, Roman games, identity and empire, religion, Christianization of Rome Mediterranean Region Signs and symbols Symbolism
-becomes-
women earli church materi cultur topographi gender late antiqu roman domest space roman game ident empir religi christian rome mediterranean region sign symbol symbol
I use OpenRefine to change the shape of the data into an edge list, then make it numerical for Gephi:
Gephi uses some version of the Louvain algorithm to find ‘communities’, or clusters, in a network. These clusters are the categories which I have displayed in the following map.
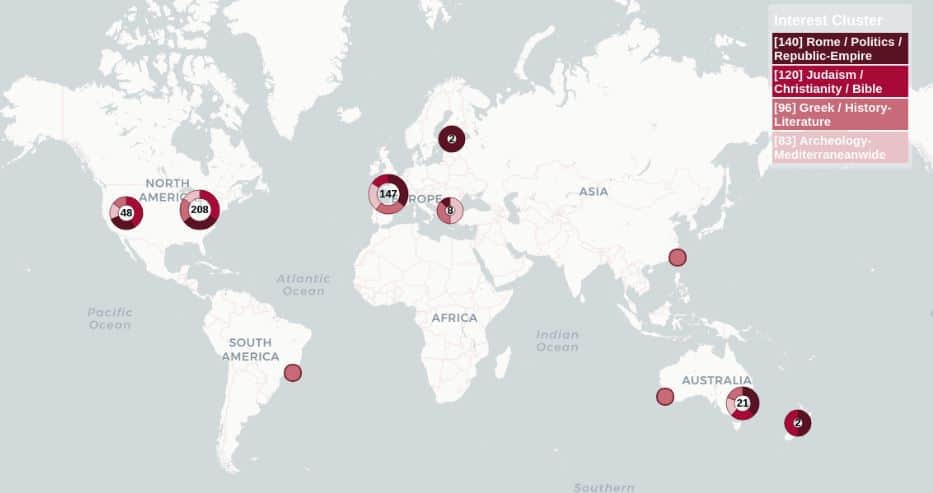
https://geog3540.github.io/woah/testing/clusterpies/713.html
Tomorrow, I will describe where the labels for the clusters come from, some challenges and experiments with clustering algorithms and using topic modeling on the stemmed and stop-word-removed texts.
Feedback is always welcome,
Ed Keogh
edward-keogh@uiowa.edu