

NASA Photo. Total Eclipse Australia, Nov. 15, 2012
I’m guessing you have heard a lot about the “Eclipse of the Century,” lately. And, you’ve no doubt heard that you shouldn’t look directly at the eclipse. But what else do you know about a total eclipse?
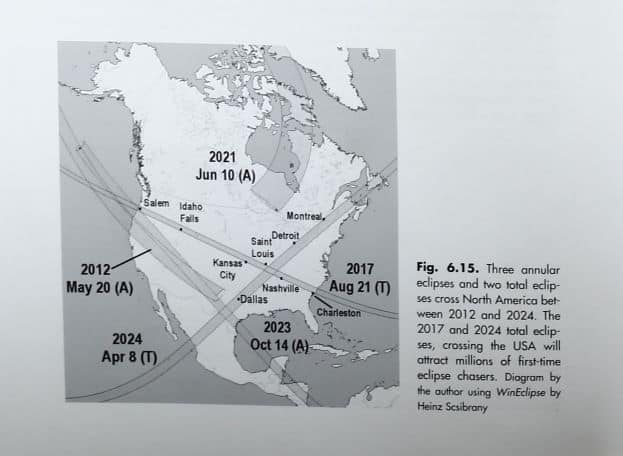
You might think that a total solar eclipse is a fairly rare event – after all, this one has been dubbed the “Eclipse of the Century.” However, a total solar eclipse occurs approximately every 18 months – or 2 total eclipses every three years. So, why is this one so special? The eclipse which will occur on August 21, 2017 at 1:12 p.m. (time for the most complete viewing in Iowa City, Iowa) is the 1st coast-to-coast total solar eclipse in 99 years! There will be total eclipses in 2019 and 2020 – but only visible below the equator. The next total eclipse which will cross the United States will occur on April 8, 2024.
Hawaii experienced a total solar eclipse in 1991, but the U.S. mainland hasn’t seen one since 1979. The Eclipse of the Century (i.e. August 21, 2017) will sweep from coast to coast! The path of totality (total darkness) will begin near Lincoln City, Oregon, crossing into Idaho, Wyoming, Nebraska, Kansas, Missouri, Illinois, Kentucky, Tennessee, Georgia, North Carolina and finally, South Carolina. Tiny slivers will pass over Montana and Iowa. Many references to the eclipse say it will pass over 12 states – “forgetting” to include Montana and Iowa! The total eclipse in Iowa will be seen on a farm in the extreme southwest corner! It is such a small corner and a such a short duration it often is ignored!
Graphic from “Total Solar Eclipses and How to Observe Them” by Martin Mobberley.
In Iowa City, the countdown to the Iowa version of the total eclipse begins at 11:47 a.m. The maximum will be reached as 1:12 p.m. and it will end at 2:36 p.m. Iowa City and the surrounding area will actually see a partial solar eclipse – the percent of the totality will be 92.22%.
Did you know there are several types of solar eclipses? A partial eclipse is when the moon obscures only a portion of the sun. An annular eclipse is a total eclipse but one in which the moon is so close to the sun they appear to be nearly the same size and the edges of the sun can be seen. A total eclipse is when the moon totally blocks the sun.

So, what causes an eclipse? We know the moon passing in front of the sun blots out the sun – but how? The length of the new moon’s shadow is – on the average – 232,100 miles. The moon’s distance to the earth’s surface is – on the average – 234,900 miles. So, when the moon passes directly in front of the sun it appears smaller than the sun – which causes the bright ring of sunlight around the moon’s silhouette!
Now you have a very basic idea of what a solar eclipse is, how is the best and safest way to actually observe it?
Looking directly at the sun is never a good idea, but is definitely not safe during an eclipse. The solar radiation that reaches the earth is known to contribute to the accelerated aging of the outer layers of the eye and the development of cataracts. Light-sensitive rods and cone cells can be severely damaged by exposure to intense visible light. It is possible there could be a temporary or permanent loss of vision from retinal burns. The danger is increased because there are no pain receptors in the retina and the effect may not show up for several hours after exposure.
Using homemade filters or very dark sunglasses is not safe. Special “eclipse glasses” and handheld solar viewers are available. However, one should be sure that those glasses and viewers are from reputable vendors and are certified as safe for eclipse viewing. The American Astronomical Society; National Science Foundation have a website, Solar Eclipse Across America, which has information about how to safely view an eclipse and a list of reputable vendors where you may purchase certified glasses, viewers, and filters. Interestingly, this website explains an alternative method of viewing the eclipse via a pinhole projection.
If you are interested in photography, you should know that taking photos of the eclipse without the proper equipment can damage your camera. Chapter 11 of Total Solar Eclipses deals with DSLRs and digital eclipse photography. Solar Eclipse Across America also has a page dedicated to shooting both still images and videos. Certified filters for telescopes, binoculars and camera lenses are also listed on the reputable vendor page.
For those of you in the Iowa City area, head to the University of Iowa Sciences Library eclipse page on their website – you’ll learn what is happening on campus, where and how you can see it, what to expect and more! If you aren’t able to get out and safely view the eclipse it will be possible to watch it online! For a list of websites which will stream live check out How to watch the total solar eclipse online – Astronomy magazine has a list of where and when the total eclipse will be live online – those of us who are not lucky enough to be in the path of the total eclipse will still be able to view it!
Want to check out what the eclipse will look like where you are? Time : Science has a simulation that shows the eclipse from any location in the United States!
How much do you know about solar eclipses? Check out this quiz from National Geographic!
Those who have experienced total eclipses say there is nothing like them and seeing one is an experience like no other. So, no matter where you are in the path of this eclipse – please be safe and ENJOY!!
Resources:
Mobberley, Martin. 2007. Total solar eclipses and how to observe them. New York : Springer. Engineering Library QB541 .M63 2007
Levy, David H. 2010. David Levy’s guide to eclipses, transits, and occulations. Cambridge ; New York : Cambridge University Press. Engineering Library QB175 .L48 2010
Solar Eclipse – August 21, 2017. University of Iowa Sciences Library. Date accessed: August 8, 2017
Zeller, Michael. 2014-2017. Eclipse Basics. Great American Eclipse. Date accessed: August 8, 2017.
Eclipses and Transits. NASA Date Accessed: August 8, 2017
Solar Eclipse Across America : Monday, August 21, 2017: Sun…Moon… You! 2017. American Astronomical Society
Chou, B. Ralph, MSc, OD. Eye Safety During Solar Eclipses. NASA, Heliophysics Science Division. Date Accessed: August, 8, 2017
Kilen, Mike. May 16, 2017. A tiny farm field is the first Iowa spot in 63 years under a total solar eclipse. The Des Moines Register.
Bell, Terena. August 1, 2017. How to watch the total solar eclipse online : viewing options for astronomy fans outside totality. Astronomy Magazine.
Wilson, Chris, Aug. 7, 2017. See How the Solar Eclipse Will Look From Anywhere in the U.S. Time : Science
Other Resources:
View the Solar Eclipse Safely. 2017. University of Iowa Hospitals & Clinics.
Zeller, Michael. 2014-2017. Future Eclipses in the 21st Century. Great American Eclipse Date accessed: August 8, 2017.
Weitering, Hanneke, Space.com Staff Writer. June 23, 2017. The Best ISO-Certified Gear to See the 2017 Solar Eclipse. space.com
August 21, 2017 – Great American Eclipse (Total Solar Eclipse). timeanddate.com
Jao, Joe. Space.com Skywatching Columnist. April 25, 2017. Total Solar Eclipses: How Often Do They Occur (and Why?). space.com.
Eclipse 101 : Safety : Eclipse Eyeglass Safety : Don’t be Blindsided! NASA . Date accessed: July 31, 2017




 BIG EVENTS FROM SUMMER 2017: UI Libraries Hosted the Rare Books and Manuscripts Conference The University of Iowa Libraries hosted the Rare Books and Manuscripts Section of the American […]
BIG EVENTS FROM SUMMER 2017: UI Libraries Hosted the Rare Books and Manuscripts Conference The University of Iowa Libraries hosted the Rare Books and Manuscripts Section of the American […]
 By Elizabeth Riordan, Graduate Assistant Last fall, Special Collections became the new home for the Tom Brokaw papers, a collection that covers the life and career of a man who […]
By Elizabeth Riordan, Graduate Assistant Last fall, Special Collections became the new home for the Tom Brokaw papers, a collection that covers the life and career of a man who […]










